Groq’s Llama 3.1 70B Speculative Decoding: A Leap in AI Performance

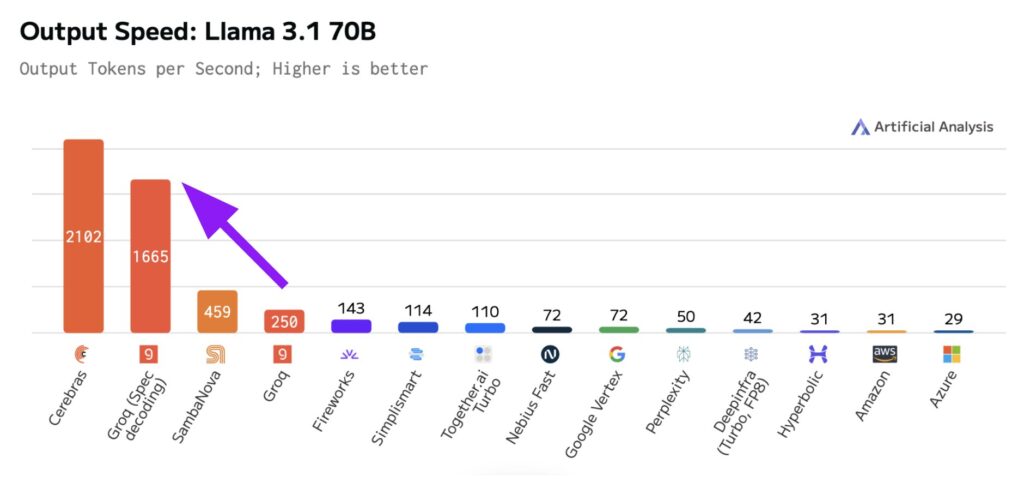
Groq has released a groundbreaking implementation of the Llama 3.1 70B model on GroqCloud, featuring speculative decoding technology. This innovation has resulted in a remarkable performance enhancement, increasing processing speed from 250 T/s to 1660 T/s. Independent benchmarks confirm that this new endpoint achieves 1,665 output tokens per second, surpassing Groq’s previous performance by over 6 times and outpacing the median of other providers by more than 20 times. The implementation maintains response quality while significantly improving speed, making it suitable for various applications such as content creation, conversational AI, and decision-making processes. This advancement, achieved through software updates alone on Groq’s 14nm LPU architecture, demonstrates the potential for future improvements in AI model performance and accessibility.
Introduction to Groq’s Llama 3.1 70B Speculative Decoding
Groq has announced a significant breakthrough in AI model performance with the release of Llama 3.1 70B Speculative Decoding (llama-3.1-70b-specdec) on GroqCloud ¹. This new implementation represents a major leap forward in processing speed and efficiency, achieved through innovative software optimizations on Groq’s existing hardware architecture.
Performance Enhancements and Benchmarks
The most striking feature of Groq’s new implementation is the dramatic increase in performance. The company reports a jump from 250 T/s to 1660 T/s, representing more than a 6x improvement over their previous Llama 3.1 70B endpoint. This enhancement has been independently verified by Artificial Analysis, a respected benchmarking firm in the AI industry ² ³.
George Cameron, Co-Founder of Artificial Analysis, stated: “Artificial Analysis has independently benchmarked Groq as serving Meta’s Llama 3.1 70B model at 1,665 output tokens per second on their new endpoint with speculative decoding. This is >6X faster than their current Llama 3.1 70B endpoint without speculative decoding and >20X faster than the median of other providers serving the model.” ¹
The performance improvements are even more pronounced for certain types of prompts. For example, when tasked with “Write out the Gettysburg Address verbatim,” the system achieved approximately 2,500 output tokens per second, demonstrating the potential for even higher speeds with less complex prompts.
Technology Behind the Breakthrough: Speculative Decoding
The significant performance gain is attributed to the implementation of speculative decoding, an innovative approach to language model processing. This technique employs a smaller, faster ‘draft model’ to generate initial token predictions, which are then verified by the primary model.
As explained by Artificial Analysis: “Speculative decoding involves using a smaller and faster ‘draft model’ to generate tokens for the primary model to verify. Our independent quality evaluations of Groq’s speculative decoding endpoint confirm no quality degradation, validating Groq’s correct implementation of the optimization technique.” ¹
This method allows for faster and more efficient processing, as verifying tokens is significantly quicker than generating them from scratch. Importantly, Groq has implemented this technique without compromising the quality of the model’s responses, as confirmed by independent evaluations.
Speculative decoding is a smart optimization technique that significantly enhances the inference speed of large language models (LLMs) ⁴ ⁵. This approach allows the model to make educated guesses about future tokens while generating the current token, all within a single forward pass. The key to its effectiveness lies in its ability to predict multiple tokens simultaneously, coupled with a verification mechanism that ensures the correctness of these speculated tokens.
The process works as follows:
- Multiple speculative heads are attached to the LLM, each predicting a subsequent token (N+1, N+2, N+3, etc.).
- These heads operate without replicating the key-value (KV) cache, maintaining efficiency.
- A verification step ensures that the speculated tokens match the original model’s output, guaranteeing accuracy.
Implementation of speculative decoding involves modifying the paged attention kernel, originally developed in the vLLM project ⁶. This modification enables efficient KV-cache maintenance without reducing throughput at larger batch sizes. Additionally, attention masks are adjusted to allow verification of speculated tokens.
The number of speculative heads can be optimized based on the model type and size. For language models, 3-4 heads typically work well, while code models can benefit from 6-8 heads. This configuration balances the trade-offs between increased compute, memory usage, and prediction accuracy.
Groq’s implementation of speculative decoding has demonstrated remarkable results, achieving a more than 6x speedup for the Llama 3.1 70B model using this technique. This significant improvement is observed across various metrics, including overall token generation speed, which increased from 250 T/s to 1660 T/s. The enhancements are consistent across different types of prompts and use cases, showcasing the robustness of Groq’s optimization technique.
Applications and Potential Use Cases
The enhanced speed and efficiency of Groq’s llama-3.1-70b-specdec implementation open up new possibilities for real-world applications of AI. The company highlights several key areas where this technology can make a significant impact:
- Agentic workflows for content creation: The increased speed allows for real-time generation of high-quality content such as articles, social media posts, and product descriptions.
- Conversational AI for customer service: The model’s rapid response capabilities make it ideal for building AI systems that can understand and respond to customer inquiries in real-time.
- Decision-making and planning: The improved processing speed enables AI models to analyze complex data and make decisions more quickly, enhancing their utility in time-sensitive scenarios.
As Groq states, “Fast AI inference, like what Groq is providing for llama-3.1-70B-specdec, is helping to unlock the full potential of GenAI. Pushing the boundaries of speed is helping make AI models more useful to real-world applications, enabling developers to build more intelligent and capable applications, and increase the intelligence and capability of openly-available models.” ¹
Hardware and Future Potential
A notable aspect of Groq’s achievement is that it was accomplished through software optimizations alone, without changes to the underlying hardware. The company’s LPU chips currently run on 14nm silicon, which is not the most advanced process technology available.
This fact suggests significant potential for future improvements. As Groq develops next-generation hardware, the combination of advanced chips with their optimized software could lead to even greater performance gains. The company expresses enthusiasm for “what this will mean for future performance potential as new models enter the AI ecosystem and as Groq matches that innovation with V2 hardware.” ¹
Availability and Pricing
Initially, access to llama-3.1-70b-specdec is exclusive to paying customers and not available on Groq’s free plan. The company has set competitive pricing for this high-performance model:
- Input tokens: $0.59 per million
- Output tokens: $0.99 per million
The context window for the model starts at 8k, providing ample capacity for a wide range of applications.
Groq emphasizes its commitment to making the model more broadly available in the coming weeks, underlining their dedication to “fueling the open AI ecosystem by providing developers with access to leading AI models that drive innovation.” ¹
Conclusion
Groq’s release of Llama 3.1 70B Speculative Decoding represents a significant advancement in AI model performance. By achieving a more than 6x increase in processing speed through software optimization alone, Groq has demonstrated the potential for substantial improvements in AI capabilities without the need for hardware upgrades.
The implementation of speculative decoding, verified by independent benchmarks, not only enhances speed but maintains the quality of model responses. This breakthrough has far-reaching implications for various AI applications, from content creation to real-time decision-making systems.
As Groq continues to refine its technology and develop new hardware, the AI community can anticipate further advancements in model performance and accessibility. This development marks an important step forward in making powerful AI models more efficient and practical for real-world applications, potentially accelerating innovation across the AI ecosystem.
Sources:
- https://groq.com/groq-first-generation-14nm-chip-just-got-a-6x-speed-boost-introducing-llama-3-1-70b-speculative-decoding-on-groqcloud/
- https://x.com/ArtificialAnlys/status/1857474573161173228
- https://artificialanalysis.ai/models/llama-3-1-instruct-70b/providers
- https://pytorch.org/blog/hitchhikers-guide-speculative-decoding/
- https://arxiv.org/abs/2211.17192
- https://github.com/vllm-project/vllm