Hymba: The Hybrid Architecture Reshaping NLP Efficiency

NVIDIA’s Hymba represents a significant advancement in small language model architecture, combining transformer attention mechanisms with state space models (SSMs) to enhance efficiency and performance in natural language processing tasks. With 1.5 billion parameters, Hymba outperforms other sub-2B models in accuracy, throughput, and cache efficiency. Key innovations include parallel processing of attention and SSM heads, meta-tokens for learned cache initialization, and cross-layer KV cache sharing. Hymba demonstrates superior performance across various benchmarks, making it suitable for a wide range of applications from enterprise AI to edge computing.
Introduction
NVIDIA has introduced Hymba ¹ ², a novel family of small language models featuring a hybrid-head parallel architecture. This innovative approach addresses the challenges faced by traditional transformer models and state space models (SSMs) by combining their strengths. Hymba aims to provide enhanced efficiency and improved performance across a wide range of natural language processing tasks.
Architectural Overview
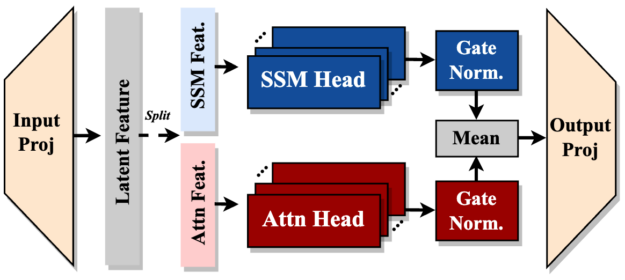
Hymba’s architecture is characterized by its unique hybrid design, which integrates transformer attention mechanisms with SSMs. This parallel processing approach allows for simultaneous information handling, combining the high-resolution recall capabilities of attention heads with the efficient context summarization of SSM heads.
Key components of the Hymba architecture include:
- Attention Heads: These function like spotlights, focusing on specific parts of input data to help the model remember important details clearly.
- SSM Heads: These summarize or condense information over time, allowing for efficient context handling.
- Meta-tokens: 128 learnable embeddings prepended to inputs, serving as learned cache initialization to enhance focus on relevant information and mitigate attention drain.
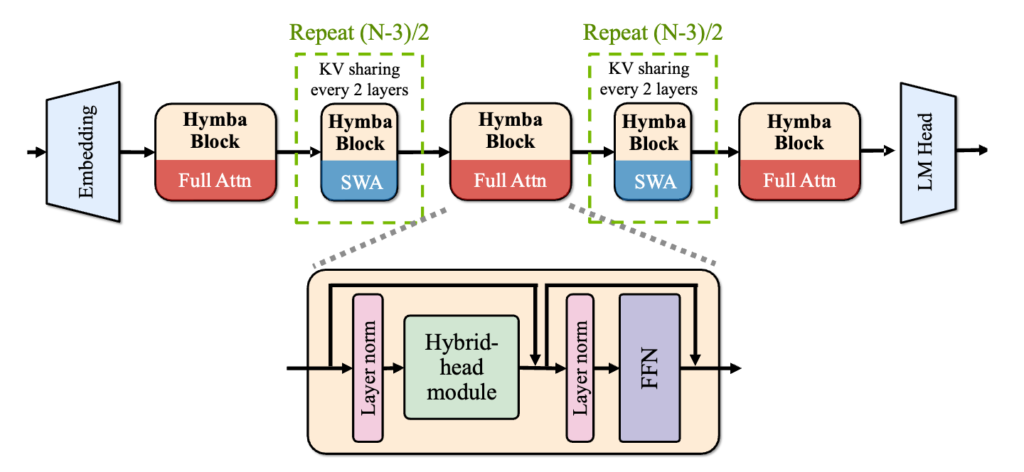
- Cross-layer KV cache sharing: Implemented between every two consecutive attention layers and between heads within the same layer, significantly reducing memory requirements.
- Sliding window attention: Full attention heads are preserved in three layers (first, last, and middle), with sliding window attention heads used in the remaining 90 layers.
The model maintains a 5:1 parameter ratio between SSM and attention heads, optimizing the balance between these two components.
Training Methodology
The training process for Hymba involves a two-stage approach for the base model:
- Stage 1: Maintains a constant large learning rate with less filtered large corpus data.
- Stage 2: Continuous learning rate decay using high-quality data.
For the instruction-tuned version, a three-stage process is employed:
- SFT-1: Focuses on developing strong reasoning abilities.
- SFT-2: Teaches the model to follow human instructions.
- DPO: Aligns the model with human preferences and improves safety.
This comprehensive training pipeline ensures that Hymba is well-equipped to handle a variety of tasks while maintaining efficiency and safety.
Performance Metrics and Efficiency
Hymba demonstrates impressive performance across various metrics:
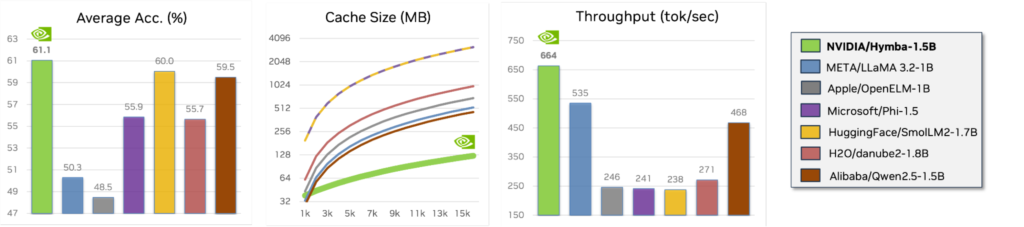
- Throughput: 664 tokens per second, significantly higher than competitors like SmolLM2 or Llama-3.2-3B.
- Cache Size: Highly efficient at 79 MB, much smaller compared to other models.
- Task Performance: High scores on various benchmarks, including MMLU, ARC-E, PIQA, and others.
In comparison to other models:
- Hymba 1.5B achieves a 1.55 average accuracy improvement, 1.41x throughput, and 2.90x cache efficiency compared to Qwen2.5.
- Compared to h2o-danube2, Hymba demonstrates a 5.41 average accuracy improvement, 2.45x throughput, and 6.23x cache efficiency.
These metrics highlight Hymba’s balanced approach, offering superior performance while maintaining efficiency in terms of computational resources and memory usage.
Real-World Applications
Hymba’s unique combination of efficiency and performance makes it suitable for a wide range of applications:
- Enterprise AI: Ideal for real-time customer service bots, search engines, and virtual assistants due to its high throughput and accuracy.
- Edge AI: The model’s low cache size and efficient processing make it suitable for deployment on smartphones, IoT devices, or autonomous vehicles.
- Research and Education: Hymba’s balance of accuracy and speed makes it valuable for academic research and educational AI applications.
- Creative Applications: The model can be used for text generation, summarization, and creative writing tasks.
Limitations and Ethical Considerations
While Hymba represents a significant advancement in small language models, it’s important to acknowledge its limitations and potential ethical concerns:
- Training Data Bias: As the model was trained on internet data, it may reflect biases present in that data and potentially produce toxic responses.
- Technical Limitations: Users should set batch size to one during generation due to current setup limitations.
- Ethical Use: NVIDIA emphasizes shared responsibility in creating trustworthy AI and advises responsible use of the model.
Testing it yourself
Hymba is an open model available for download and experimentation. NVIDIA has released two versions of the model on Hugging Face:
- Hymba-1.5B-Base ³
- Hymba-1.5B-Instruct. ⁴
The base model is designed for various natural language generation tasks, while the instruct version is fine-tuned for complex tasks like math reasoning, function calling, and role-playing. Both models can be easily accessed and integrated into projects using the Hugging Face Transformers library, allowing researchers and developers to explore the capabilities of this innovative architecture firsthand.
Conclusion
NVIDIA’s Hymba represents a significant leap forward in small language model architecture. By combining the strengths of transformer attention mechanisms and state space models, Hymba achieves superior performance across a wide range of tasks while maintaining high efficiency in terms of throughput and memory usage compared to similarly sized small language models. Its balanced approach to parameter size, cache efficiency, and accuracy makes it a versatile tool for various applications, from enterprise-level AI to edge computing.
The model’s innovative features, such as meta-tokens and cross-layer KV cache sharing, demonstrate the potential for further advancements in language model architecture. As AI continues to advance, Hymba represents a significant step forward for small language models. Its innovative architecture sets new standards for performance and efficiency, particularly for edge computing applications. By demonstrating what’s possible with compact models, Hymba opens up new possibilities for more accessible and versatile AI capabilities across various industries.
However, as with all AI models, it’s crucial to consider the ethical implications and potential biases inherent in the training data. Responsible use and continued research into mitigating these issues will be essential as Hymba and similar models become more widely adopted.
Hymba’s release marks an important milestone in the development of efficient and powerful language models, paving the way for more accessible and versatile AI applications across various domains.
Sources: