Extending the Limits: Alibaba’s Qwen2.5-Turbo and the 1M Token Milestone

Alibaba Cloud’s Qwen team has unveiled Qwen2.5-Turbo, a groundbreaking update to their language model that extends context length to 1 million tokens. This advancement enables processing of vast amounts of text equivalent to 10 full-length novels or 30,000 lines of code. The model demonstrates superior performance in long-text comprehension tasks, outperforming competitors like GPT-4 on benchmarks such as RULER. Notably, Qwen2.5-Turbo achieves a 4.3x speedup in processing time through sparse attention mechanisms while maintaining cost-effectiveness. Despite these improvements, the team acknowledges challenges in long sequence task performance and plans further optimizations. This release marks a significant step forward in AI’s capability to handle and understand extensive contextual information.
Introduction
The field of artificial intelligence continues to advance with the release of Qwen2.5-Turbo ¹ by Alibaba Cloud’s Qwen team. This latest iteration of their language model joins the ranks of other models capable of processing long contexts. The new Qwen2.5-Turbo language model addresses a critical demand in the AI community: the ability to process and comprehend extraordinarily long texts. The extension of the model’s context length from 128,000 to 1 million tokens represents a welcome advancement in AI’s capacity to handle complex, lengthy texts and code bases.
Extended Context Capabilities
Qwen2.5-Turbo’s expanded context length of 1 million tokens translates to approximately:
- 1 million English words
- 1.5 million Chinese characters
- 10 full-length novels
- 150 hours of speech transcripts
- 30,000 lines of code
This extension allows for unprecedented applications in deep understanding of long novels, repository-level code assistance, and comprehensive analysis of multiple academic papers. The model’s ability to process such vast amounts of information in a single context opens new possibilities for AI applications across various industries and academic fields.
Performance Benchmarks
Qwen2.5-Turbo has demonstrated impressive performance across several benchmark tests:
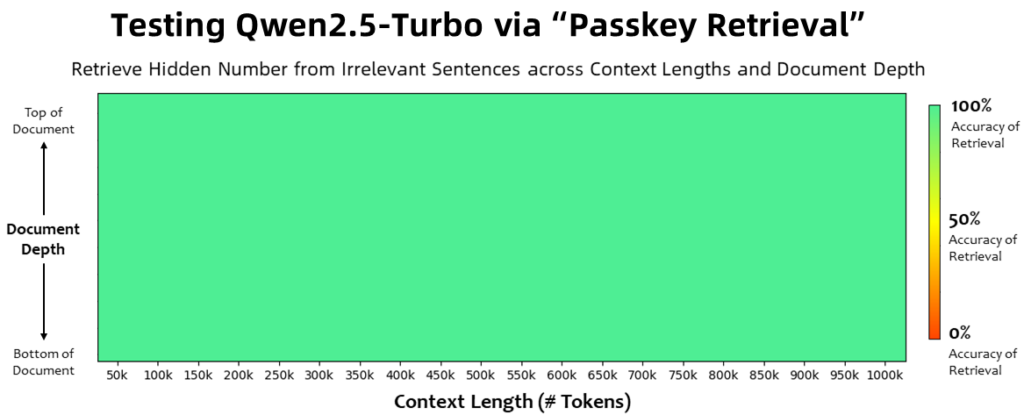
- Passkey Retrieval Task:
The model achieved 100% accuracy in the 1M-token Passkey Retrieval task, showcasing its ability to capture and retrieve specific details within an extensive context reliably. - RULER Benchmark:
Qwen2.5-Turbo scored 93.1 on the RULER benchmark, surpassing both GPT-4 (91.6) and GLM4-9B-1M (89.9). This performance underscores the model’s superior capabilities in long text comprehension tasks. - Additional Long Text Comprehension Benchmarks:
The model outperformed GPT-4 and GLM4-9B-1M in various other long text comprehension benchmarks. - Short Sequence Performance:
Notably, Qwen2.5-Turbo maintains strong performance on short sequences, demonstrating capabilities on par with GPT-4o-mini. This indicates that the extension of context length has not compromised the model’s efficiency in handling shorter texts.
Technical Improvements and Efficiency
One of the most significant achievements of Qwen2.5-Turbo is the substantial improvement in processing speed:
- The time required to process 1M tokens has been reduced from 4.9 minutes to 68 seconds, representing a 4.3x speedup.
- This improvement was achieved through the implementation of sparse attention mechanisms, which compress the computation of attention by approximately 12.5 times.
These enhancements in processing speed are crucial for practical applications, especially when dealing with extensive datasets or real-time analysis of long texts.
Cost-Effectiveness
Despite the significant improvements in capabilities and performance, Qwen2.5-Turbo maintains a competitive pricing structure:
- The price remains at 0.3 yuan (approximately 4 cents) per 1 million tokens.
- At this rate, Qwen2.5-Turbo can process 3.6 times more tokens than GPT-4o-mini for the same cost.
This pricing strategy enhances the model’s accessibility and makes it an attractive option for businesses and researchers dealing with large-scale text processing tasks.
Practical Demonstration
To showcase the model’s capabilities, the Qwen team conducted a practical demonstration:
- Qwen2.5-Turbo successfully processed and summarized all three volumes of “The Three-Body Problem” by Cixin Liu.
- The total token count for this task was 690,000.
- The model completed the processing and summarization in just 45 seconds.
This demonstration highlights Qwen2.5-Turbo’s ability to efficiently handle complex, lengthy texts and extract meaningful summaries, a task that would be challenging for many existing AI models.
Availability and Integration
Qwen2.5-Turbo is now accessible through multiple platforms:
- Available via the Alibaba Cloud Model Studio API
- Demos are provided on both HuggingFace and ModelScope platforms
- The API is compatible with the OpenAI standard, facilitating easy integration into existing systems and workflows
This wide availability ensures that developers and researchers can readily incorporate Qwen2.5-Turbo into their projects and benefit from its advanced capabilities.
It’s important to note that while previous versions of Qwen2.5 were open source with freely available weights, this new version of Qwen2.5-Turbo is currently only accessible through API calls. This change in availability strategy may impact how researchers and developers interact with and utilize the model, potentially limiting some forms of experimentation and customization that were possible with the open-source versions.
Future Developments and Challenges
While Qwen2.5-Turbo represents a significant advancement, the Qwen team acknowledges several areas for future improvement:
- There is room for enhancement in long sequence task performance and stability.
- The team plans to explore human preference alignment specifically for long sequences.
- Efforts will be made to further optimize inference efficiency to reduce computation time.
- Development of larger and more powerful long-context models is on the roadmap.
These future developments aim to address current limitations and push the boundaries of AI language models even further.
Conclusion
The release of Qwen2.5-Turbo marks a significant milestone in the evolution of AI language models. Its ability to process and comprehend contexts of up to 1 million tokens, combined with improved processing speed and maintained cost-effectiveness, positions it as a powerful tool for a wide range of applications. From deep literary analysis to complex code comprehension, Qwen2.5-Turbo opens new possibilities in AI-assisted tasks. While Qwen2.5-Turbo represents a significant advancement in long-context processing, challenges remain in optimizing performance and addressing potential limitations. The team’s ongoing work will focus on improving efficiency, stability, and real-world applicability of the model. As AI language models continue to evolve, Qwen2.5-Turbo’s impact on various industries and research fields will depend on its ability to consistently deliver reliable and meaningful results in complex, long-text scenarios.
Sources: