OLMo 2: Advancing True Open-Source Language Models

Ai2 has released OLMo 2, a new family of fully open-source language models that significantly advances the field of truly open-source AI. Available in 7B and 13B parameter versions, these models demonstrate performance competitive with or surpassing other open-source and proprietary models in the same parameter range. Trained on up to 5 trillion tokens, OLMo 2 incorporates innovative techniques in training stability, staged learning, and post-training methodologies. The release includes comprehensive documentation, evaluation frameworks, and instruct-tuned variants, setting a new standard for transparency and accessibility in AI development. This breakthrough narrows the gap between open and proprietary AI systems, potentially accelerating innovation in the field.
Introduction
The landscape of artificial intelligence, particularly in the domain of natural language processing, has been rapidly evolving. However, a persistent challenge has been the dominance of proprietary models, which often outperform their open-source counterparts due to extensive resources and optimized training pipelines. This disparity has limited accessibility and innovation in AI, as only well-funded organizations could afford to develop cutting-edge technology.
In response to this challenge, the Allen Institute for AI (Ai2) has introduced OLMo 2, a groundbreaking family of open-source language models ¹. This release represents a significant step towards democratizing advanced AI capabilities and narrowing the performance gap between open and proprietary systems.
Model Architecture and Training
OLMo 2 is available in two primary configurations: a 7 billion parameter model (OLMo-2-1124-7B) and a 13 billion parameter model (OLMo-2-1124-13B). These models build upon the foundation set by the first OLMo release, incorporating several key architectural improvements to enhance performance and stability.
The training process for OLMo 2 employed a sophisticated two-stage approach. In the initial stage, which covered over 90% of the total pretraining budget, the models were trained on the OLMo-Mix-1124 dataset. This massive collection of approximately 3.9 trillion tokens was sourced from high-quality repositories including DCLM, Dolma, Starcoder, and Proof Pile II. The 7B model was trained for approximately one epoch on this dataset, while the 13B model extended to 1.2 epochs, reaching up to 5 trillion tokens.
The second stage of training involved fine-tuning on the Dolmino-Mix-1124 dataset, a carefully curated collection of 843 billion tokens. This dataset combines high-quality web data with domain-specific content from academic sources, Q&A forums, instruction data, and math workbooks. The team created multiple mixes of 50 billion, 100 billion, and 300 billion tokens, each balancing general and specialized content.
To optimize performance, the researchers employed innovative techniques such as model souping, which merges multiple model checkpoints. For the 7B model, three copies were trained on a 50B token mix and then merged. The 13B model underwent a similar process but with larger token mixes, including one model trained on 300B tokens.
Technical Innovations
The development of OLMo 2 introduced several technical innovations that contributed to its impressive performance. One of the key focus areas was training stability, which is crucial for maintaining consistent performance during long pretraining runs. The team implemented techniques such as switching from nonparametric layer norm to RMSNorm, reordering layer normalization, and employing QK-Norm. They also replaced absolute positional embeddings with rotary positional embedding and incorporated Z-loss regularization ¹.
Another significant innovation was the staged training approach, which allowed for targeted interventions during late pretraining. This method enabled the team to address knowledge or capability deficiencies discovered during the course of long training runs. By applying learning rate annealing and adjusting the data curriculum late in the pretraining process, they could effectively “patch” model capabilities that weren’t successfully acquired earlier in training.
The researchers also developed an actionable evaluation framework called OLMES (Open Language Modeling Evaluation System). This suite of 20 evaluation benchmarks was designed to assess core capabilities such as knowledge recall, commonsense reasoning, and mathematical reasoning. OLMES played a crucial role in guiding improvements through various development stages and provided a standardized way to compare OLMo 2’s performance against other models.
Performance and Benchmarks
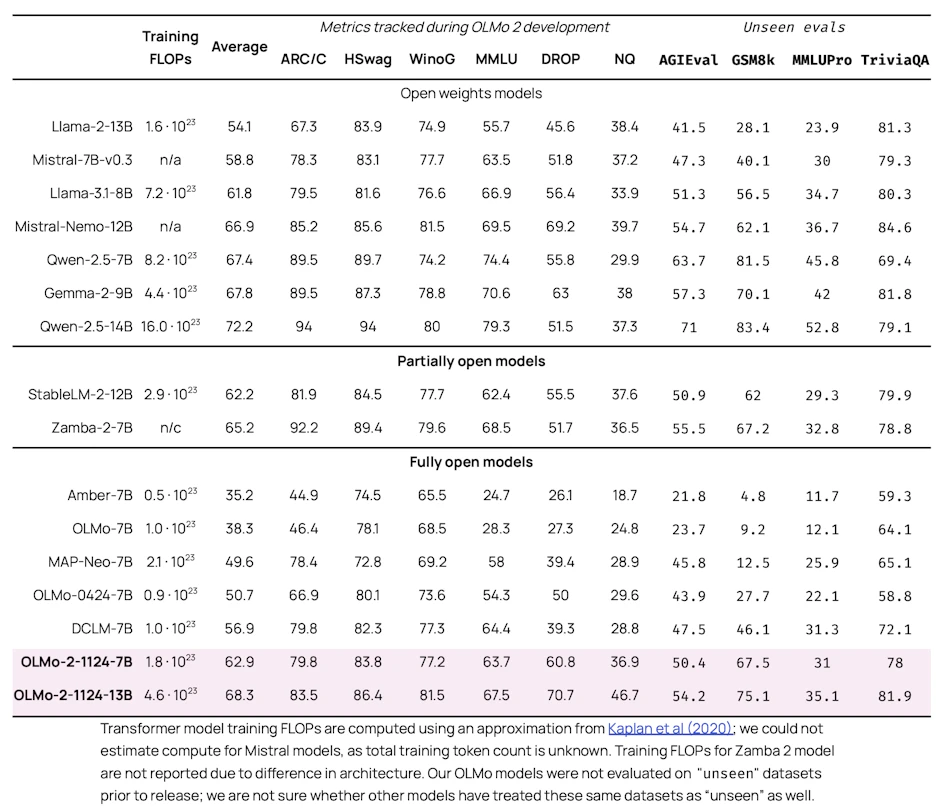
OLMo 2 has demonstrated impressive performance across a wide range of benchmarks, often matching or exceeding the capabilities of other open-source models and remaining competitive with proprietary systems. The 7B version of OLMo 2 notably outperforms Meta’s Llama 3.1 8B on several English academic benchmarks, while the 13B version surpasses Qwen 2.5 7B, despite utilizing fewer training FLOPs.
The researchers evaluated OLMo 2 using both development benchmarks, which were tracked during the model’s creation, and unseen tasks, which were only assessed after development was complete. This approach ensures a more robust evaluation of the model’s generalization capabilities. Development benchmarks included tasks like ARC Challenge, HellaSwag, WinoGrande, MMLU, DROP, and Natural Questions. Unseen evaluations comprised AGIEval, MMLU Pro, GSM8k, and TriviaQA.
Particularly noteworthy is the performance of the instruct-tuned variants of OLMo 2. These models, which underwent additional training using the Tülu 3 methodology ², have shown exceptional results on tasks requiring instruction following and complex reasoning. For instance, OLMo 2 13B Instruct outperforms models like Qwen 2.5 14B instruct, Tülu 3 8B, and Llama 3.1 8B instruct across various benchmarks, including challenging tasks like GSM8K and MATH.

Implications for Open-Source AI
The release of OLMo 2 represents a significant milestone in the development of truly open-source AI. By providing full access to training data, code, model weights, and development processes, Ai2 has set a new standard for transparency and reproducibility in AI research. This level of openness not only allows for thorough scrutiny of the model’s capabilities and limitations but also enables other researchers to build upon this work, potentially accelerating the pace of innovation in the field.
While models like Llama 3, Qwen, and DeepSeek have made significant strides in open-source AI by publishing their model weights, they still fall short of true openness by withholding crucial information about their training methodologies and data sources. In contrast, OLMo 2 represents a paradigm shift towards full transparency in AI development. By publishing not only the model weights but also the complete training pipeline, data sources, and evaluation frameworks, OLMo 2 enables thorough replication and analysis of its development process. OLMo 2’s commitment to ethical data sourcing sets a new standard for responsible AI development. This comprehensive approach to openness not only fosters trust but also accelerates innovation by allowing researchers to build upon a fully transparent foundation.
The performance of OLMo 2, which rivals that of some proprietary models in the same parameter range, demonstrates that open-source efforts can produce highly competitive AI systems. This narrows the gap between open and closed AI development, potentially democratizing access to advanced language models and fostering a more inclusive AI ecosystem.
The comprehensive release of OLMo 2, including all intermediate checkpoints and evaluation frameworks, provides valuable resources for the AI research community. This wealth of information can serve as a foundation for future studies, enabling researchers to gain deeper insights into the training and optimization of large language models.
Conclusion
The introduction of OLMo 2 by Ai2 marks a significant advancement in the field of open-source language models. Through innovative training techniques, architectural improvements, and a commitment to full transparency, OLMo 2 has achieved performance levels that compete with both open and proprietary models. This breakthrough not only pushes the boundaries of what’s possible with open-source AI but also has the potential to accelerate collaborative innovation in the field.
As AI continues to play an increasingly important role in various applications, from scientific research to everyday tasks, the availability of powerful, fully open models like OLMo 2 becomes crucial. By providing unrestricted access to high-performance AI models, Ai2 is paving the way for more equitable technological advancements and fostering an environment where researchers and developers worldwide can contribute to the progression of AI technology.
The success of OLMo 2 serves as a testament to the power of open collaboration and sets a new benchmark for future developments in language modeling. As the AI community builds upon this foundation, we can anticipate further innovations that will continue to narrow the gap between open and proprietary AI systems, ultimately leading to more accessible and powerful AI technologies for all.
Sources:
[…] https://www.theaiobserver.com/olmo-2-advancing-true-open-source-language-models/ […]